My own turning point with these tools came a good while back, in the early months of building with them. We hear endlessly about training an LLM, so I had assumed, like most people, that training covered everything. That somewhere in that vast process a system could absorb the specifics of a business. Then the building work showed me where the specifics actually enter. Training only makes the machine function. It teaches it language, reasoning, the general shape of the world. The specifics arrive afterwards, through indexing, and indexing is older, humbler technology. Filing, in effect. The part of the system that knows your business turns out to be the part that has nothing to do with AI.
Most senior people I speak to in AEC have used one of these tools by now. They have watched it draft a letter, summarise a forty page report, produce a passable first pass at a scope description. What it can do is visible to everyone. What it actually is remains foggy. And the fog matters, because it is quietly shaping how firms decide to use the thing.
So here is the plain version, the one I wish someone had given the industry two years ago.
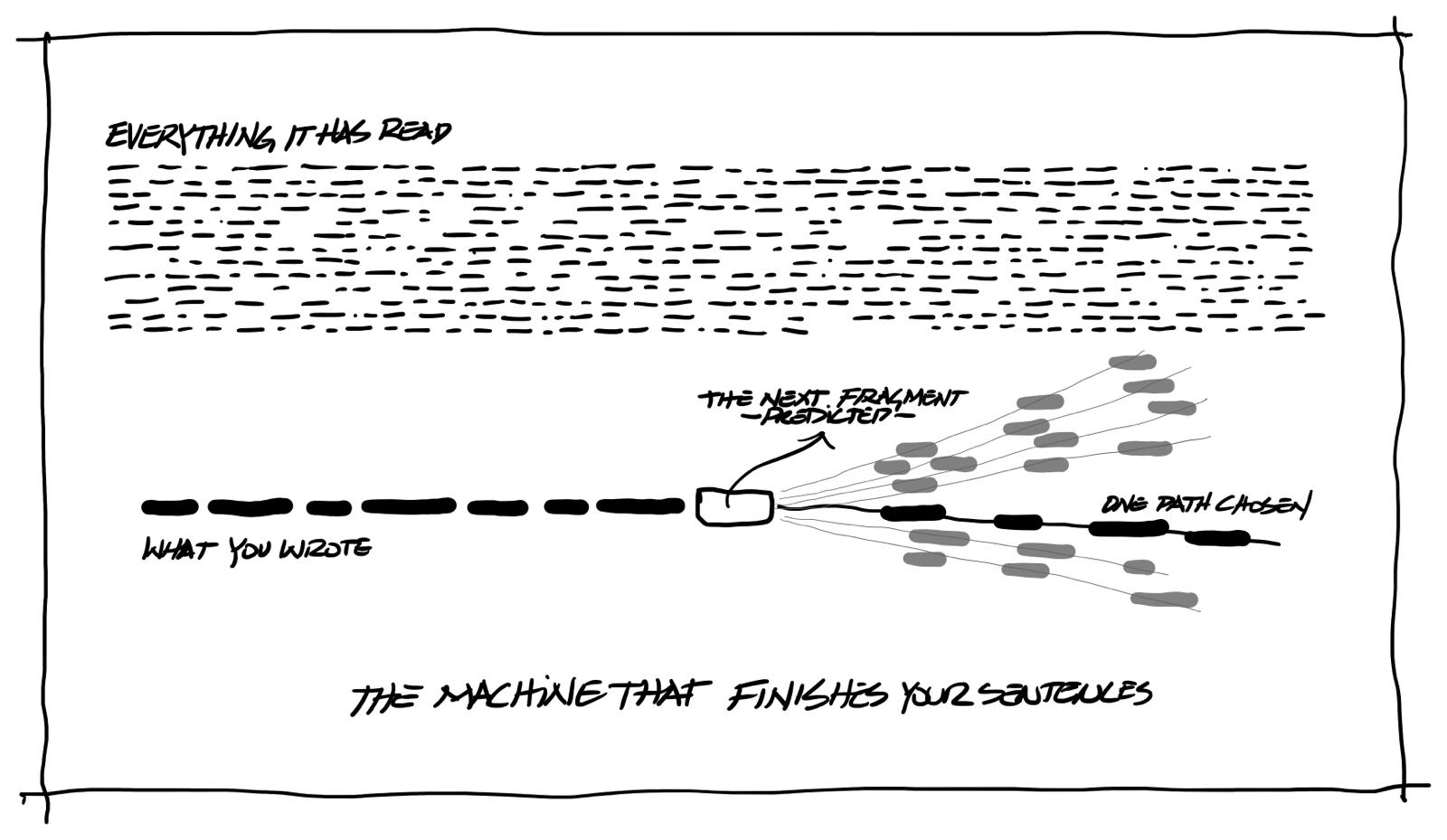
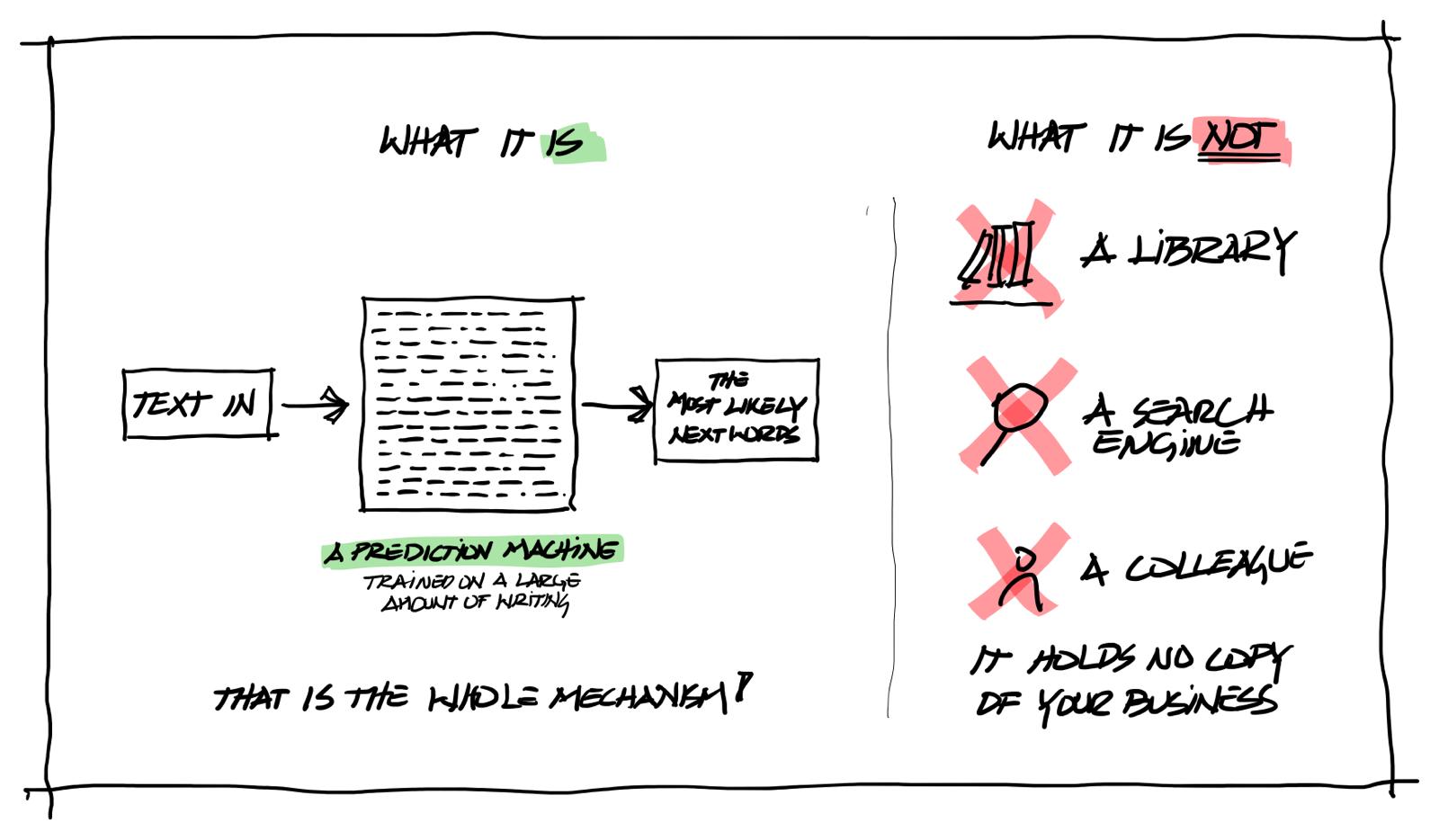
A large language model is a prediction machine for text. It has read an enormous amount of writing, and from all that reading it learned the patterns of how words follow other words. When you ask it something, it does one job: it predicts, fragment by fragment, what a good answer would look like. That is the whole mechanism. It does this astonishingly well. Well enough that it feels like understanding, and for many everyday purposes it behaves like understanding.
Now notice what is absent from that description. The model does not look anything up. Out of the box it holds no copy of your project files, your specifications, your fee history, your lessons learned. Ask it a question about your business and it answers from pattern memory, the way a very well read colleague might answer confidently about a project he never worked on. Fluent. Plausible. Unanchored.
That sounds dismissive of the technology. It is not meant to be. The prediction machine is a genuine breakthrough. My point is that the machine alone is only one piece of what makes these systems useful, and it is the piece everyone can already see.
The pieces nobody talks about
When an AI system gives accurate, specific, dependable answers about a particular domain, the model is rarely what changed. Two quieter things did.
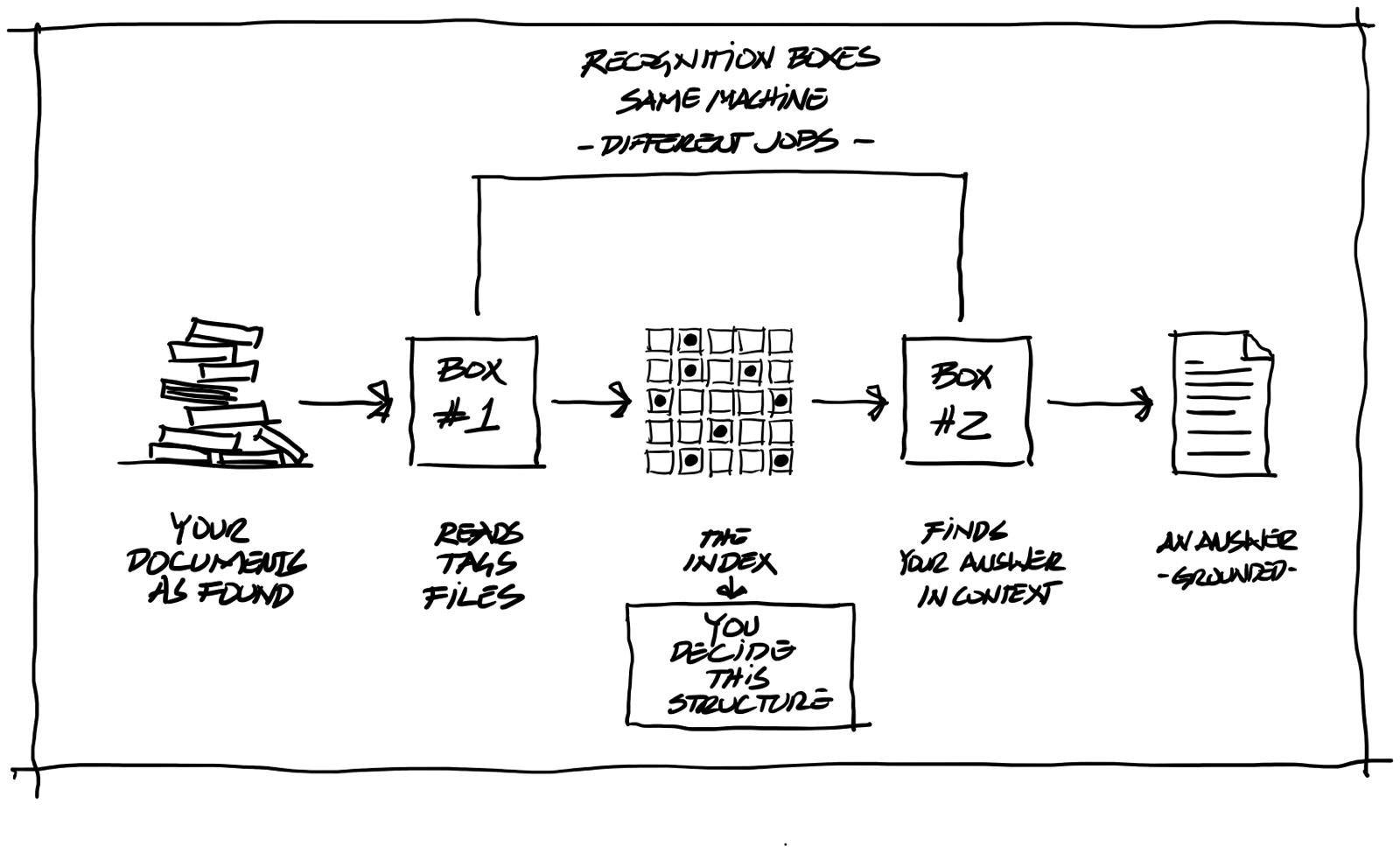
The first is the structure of the information around it. The systems that work do something deceptively simple: before the model answers, they find the right documents and hand them over, so the answer is grounded in your material rather than in pattern memory. The trade calls this retrieval, and it runs on the indexing I described at the top. Search and filing technology, decades old in spirit, doing the quiet work while the model takes the credit. The quality of it depends almost entirely on how your information is organised. A clean, well structured archive lets the system find the three paragraphs that matter. A shared drive with fifteen years of folders named “Final_v2_USE THIS ONE” gives the machine noise, and the machine will summarise the noise with total confidence.
The second is instructions. A focused system has been told, carefully and at length, what it is for. Which sources count. What it must check before answering. What it should refuse to guess at. The difference between a generic chat window and a dedicated assistant that actually knows your practice is mostly a few thousand words of well written instruction the user never sees. I spend a good portion of my working week writing and refining exactly this kind of material, and I can tell you the model is the same on both sides of that comparison. The behaviour is not.
Take TrueTrack, one of our own projects, where intelligence was central to the product from day one. It helps engineering teams capture their R&D activity as they go, so that at year end a tax relief claim can stand on real evidence. Our early version kept records the way most firms keep records: free text, attached files, the meaning buried somewhere in the notes. The AI we pointed at it produced fluent waffle. The fix had very little to do with the AI. We redesigned the records themselves, so each activity states plainly the things an assessor will actually look for, with a daily log sitting behind it. Same model, same questions. Now it reads the evidence line by line and tells you which activities would survive scrutiny. The intelligence had been available the whole time. The structure was what we had been missing.
Horses for courses
A fair question at this point: if structure matters this much, can the AI build the structure for you? It can help, and here I have to soften something I said at the top. I called indexing the part that has nothing to do with AI. That was a little too clean. In practice, firms increasingly use one system to read, classify, and file material properly so that another can later retrieve it in context. The same recognition machinery, pointed at two different stages of the process.
The misconception sits elsewhere. People assume the machine will simply do the job as found, mess and all. It will try. And it will do a far better job of filing, and later of finding, when the humans have first decided what good structure looks like. Horses for courses, in the end. Each stage uses the intelligence differently, and every stage repays preparation. We should be helping the technology help us. It returns the favour out of all proportion.
The trap of the helpful chat
Here is the pattern I keep seeing, and it worries me more than any hallucination story.
A team opens a chat window and asks it to help with the existing process. Speed up the report. Tidy the minutes. Draft the section. And it helps, every single time, because helping is what it is built to do. Output goes up. It feels like production, and that feeling is mildly addictive.
But the old process was built around old constraints. Around what people could read, hold in their heads, and check by hand. Pour acceleration into that process and you automate its assumptions along with its tasks. Two years on, the team is producing more of something the new tools should have made unnecessary, and the gap between them and the firms who restructured first has become expensive to close. Faster is a seductive substitute for better, and it compounds in the wrong direction.
This is, when you strip it back, an early decision problem. The choice of how to bring these tools into a practice is being made right now, casually, by whoever opened the chat window first. In my consulting work at Vector56 I keep returning to the same figure: 80% of innovation risk is created during concept design, long before anything visible gets built. The same holds here. The expensive mistake is almost never the tool you bought. It is the structure you skipped.
The question worth asking
So the useful question for a leadership team sits upstream of any product choice: is our information organised, and are our instructions clear enough, that any of these machines could do its best work for us?
If the answer is no, the chat window will still flatter you for a long while. That is rather the problem.
The plain version has served me better than the impressive one: the intelligence is in the machine, and the usefulness is in the structure you build around it. One you can rent from any provider. The other you have to earn.
Originally published on LinkedIn.